Tech
For computational devices, talk isn’t cheap: Research reveals unavoidable energy costs across all communication channels
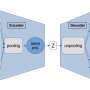
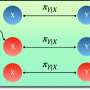
Every task we perform on a computer—whether number crunching, watching a video, or typing out an article—requires different components of the machine to interact with one another. “Communication is massively crucial for any computation,” says […]